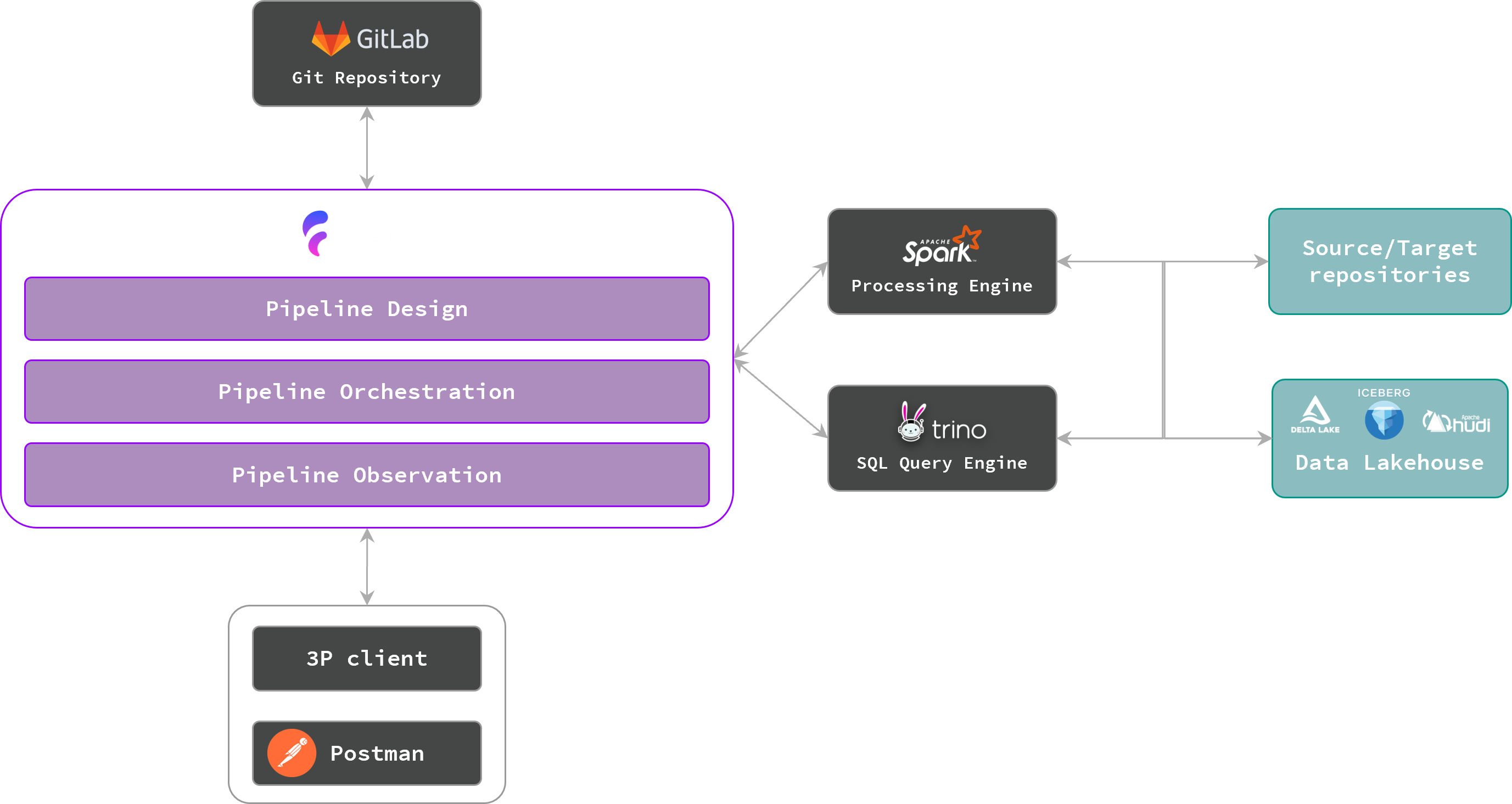
Fyrefuse is built to make data engineering job more easy and fast—from setup to day-to-day operations. In a few clicks, you can orchestrate pipelines, run processing jobs, and explore data with SQL—without stitching together a dozen tools.
Data Pipelines Design, Build, Orchestration and Observation for Data Engineers with precision of code and speed of drag and drop.
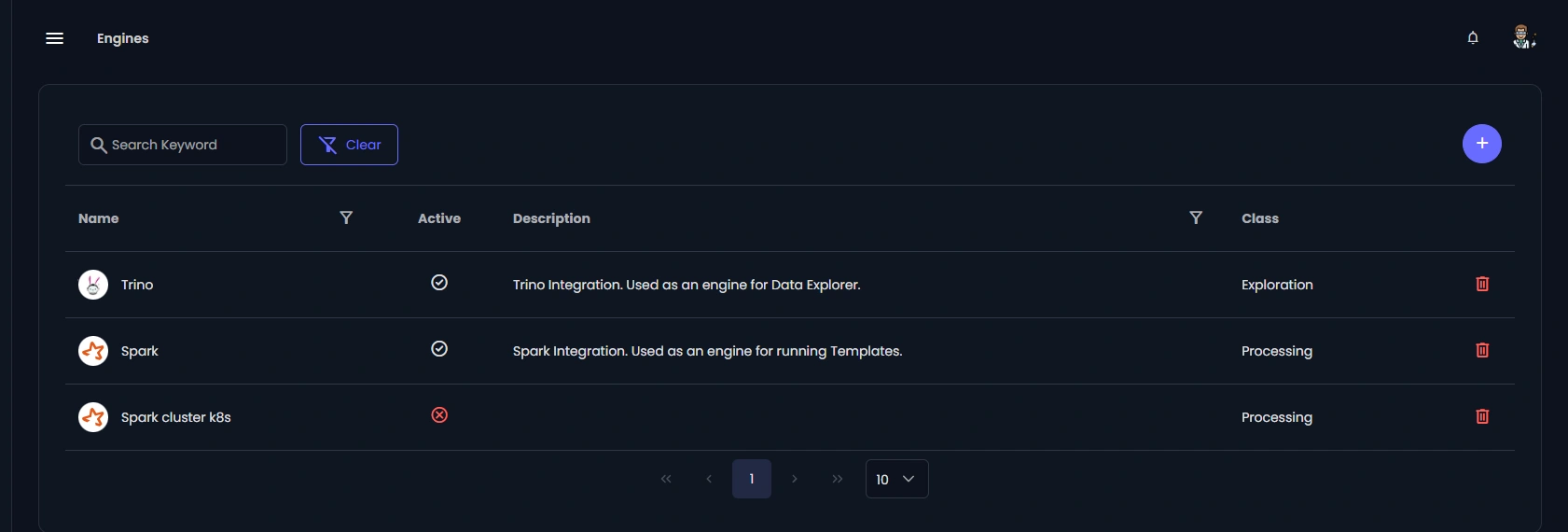
Run batch or streaming with Apache Spark, observe with Trino, and land curated datasets in your lakehouse or any enterprise-grade destination.
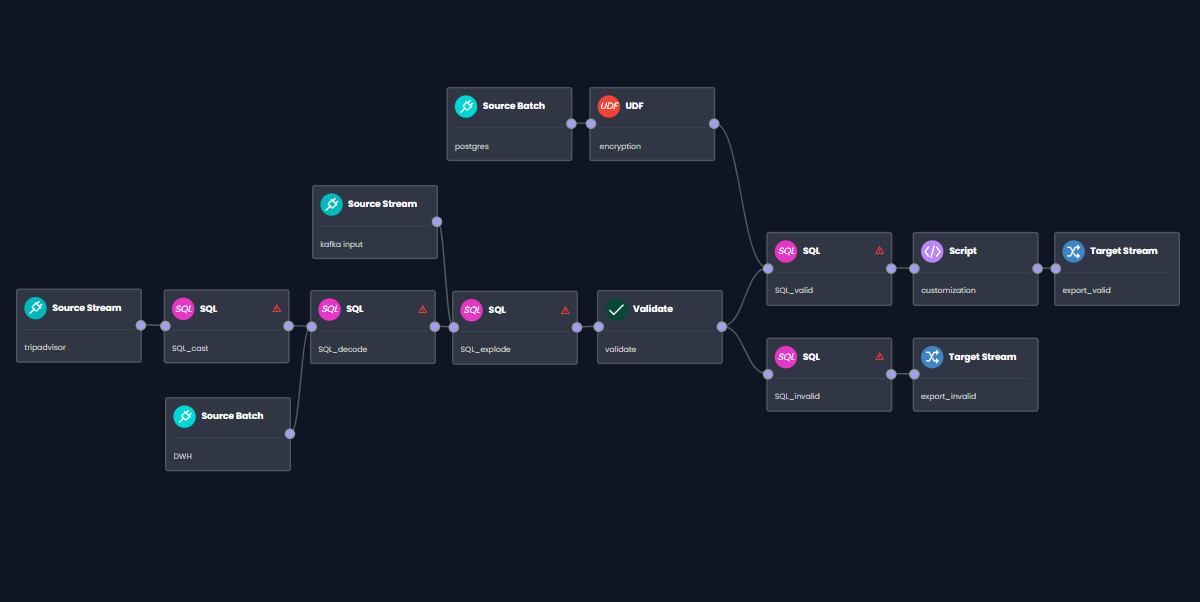
Fyrefuse automates data workflows from source to destination—coordinating ingestion, transformation, and execution through one unified control plane. Build pipelines fast, Run them precisely and Scale without friction
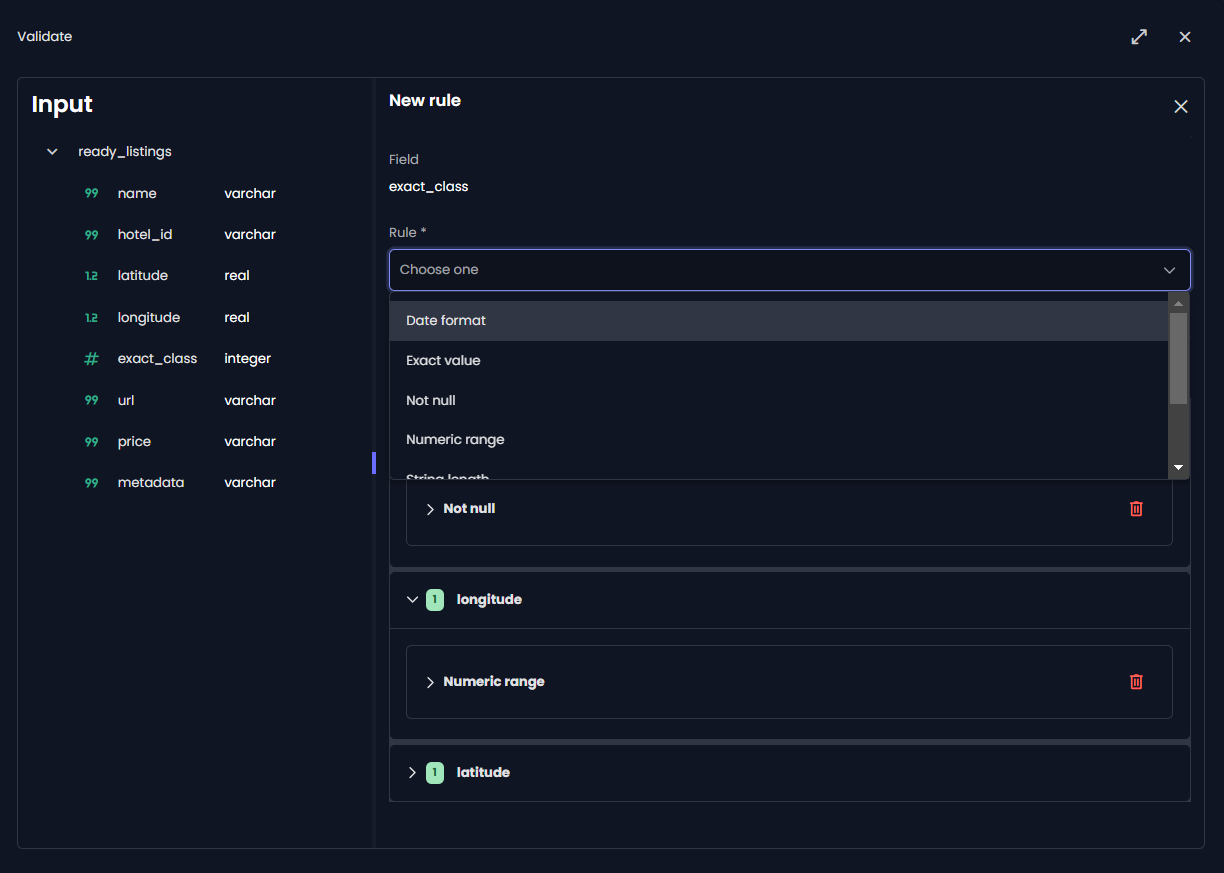
fyrefuse ensures data quality through rigorous validation and cleansing procedures, enhanced with customizable rules to ensure utmost accuracy and reliability. By swiftly detecting and rectifying discrepancies, fyrefuse upholds data integrity across both batch and real-time streams, thereby bolstering dependable analytics and decision-making.
Automates data validation and cleansing for accuracy.
Rule-based quality checks for data integrity and reliability.
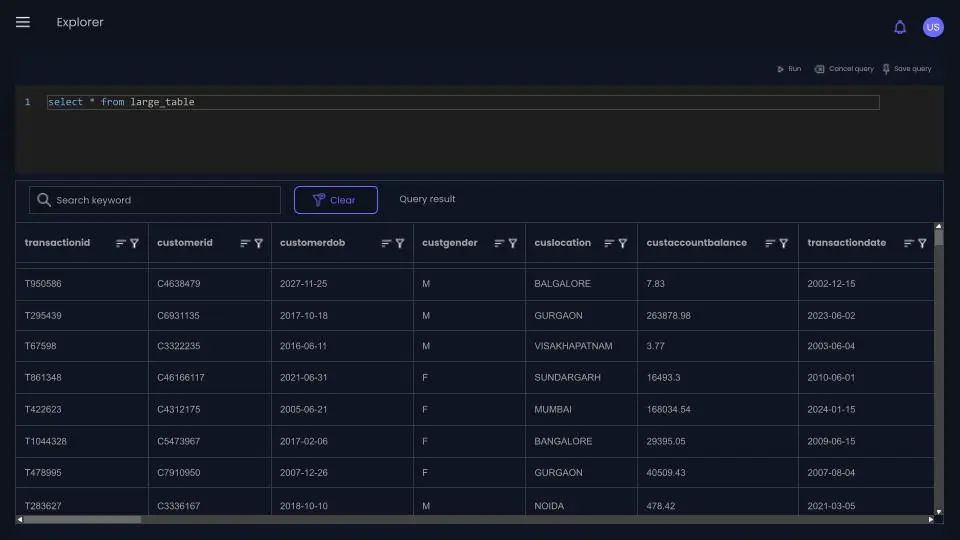
fyrefuse facilitates in-depth exploration of ingested data and provides support for many popular BI tools by integrating the powerful Trino SQL engine. It allows the execution of complex queries and commands, enabling users to extract valuable insights from their datasets efficiently and effectively. Fyrefuse, coupled with Trino, provides a dynamic and scalable solution tailored to meet the diverse needs of modern data-driven organizations.
Integrated query engine compatible with numerous BI tools.
Streamlined exploration for efficient, in depth data analysis.
fyrefuse leverages open-source technologies to simplify the training and operationalization of AI, ML and GenAI models. It facilitaties MLOps from development and training to deployment making a game-changer for data-driven decision-making.
Tools for training and deploying ML, AI, and GenAI models.
Simplified model lifecycle management for operational efficiency.
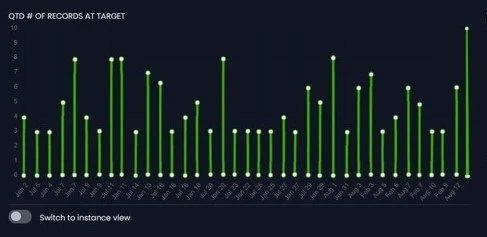
Fyrefuse not only offers comprehensive monitoring and performance metrics for your data pipelines but also automatically generates intuitive dashboards upon them. This dual functionality ensures meticulous tracking of data flow and errors, allowing for swift detection and resolution of any issues that may arise. By providing real-time insights into the health and efficiency of your pipelines, fyrefuse enables you to maintain peak performance levels and optimize your data operations seamlessly.
Comprehensive tracking of data flow, throughput and errors.
Proactive issue detection for uninterrupted operational excellence.
Our tech's key features are designed for data architects, data scientists and citizen developers and stand out to leverage industrial AI at scale.